Interactive Object Understanding
|
|
|
|
|
| Abstract: Interactive object understanding, or what we can do to objects and how is a long-standing goal of computer vision. In this paper, we tackle this problem through observation of human hands in in-the-wild egocentric videos. We demonstrate that observation of what human hands interact with and how can provide both the relevant data and the necessary supervision. Attending to hands, readily localizes and stabilizes active objects for learning and reveals places where interactions with objects occur. Analyzing the hands shows what we can do to objects and how. We apply these basic principles on the EPIC-KITCHENS dataset, and successfully learn state-sensitive features, and object affordances (regions of interaction and afforded grasps), purely by observing hands in egocentric videos. |
||
|
|
Learning State Sensitive Features
 |
||
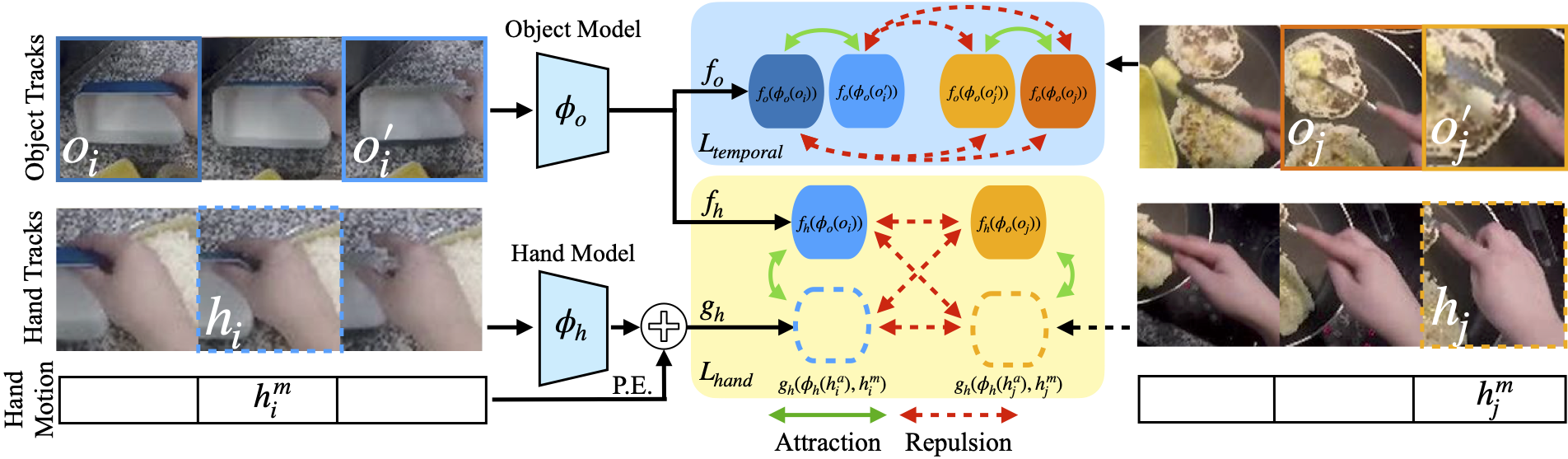
| Approach. Our self-supervised formulation builds upon two key ideas: consistency of object states in time and with hand pose. Our training objective encourages object crops, that are close in time or are associated with similar hand appearance and motion, to be similar to one another; while being far from random other object crops in the dataset. |
 |
||
| Results. Our proposed model TSC+OHC learns features better than ImageNet-pretrained features. The resulting space puts objects in similar states closer to each other. |
Learning Object Affordances
 |
||
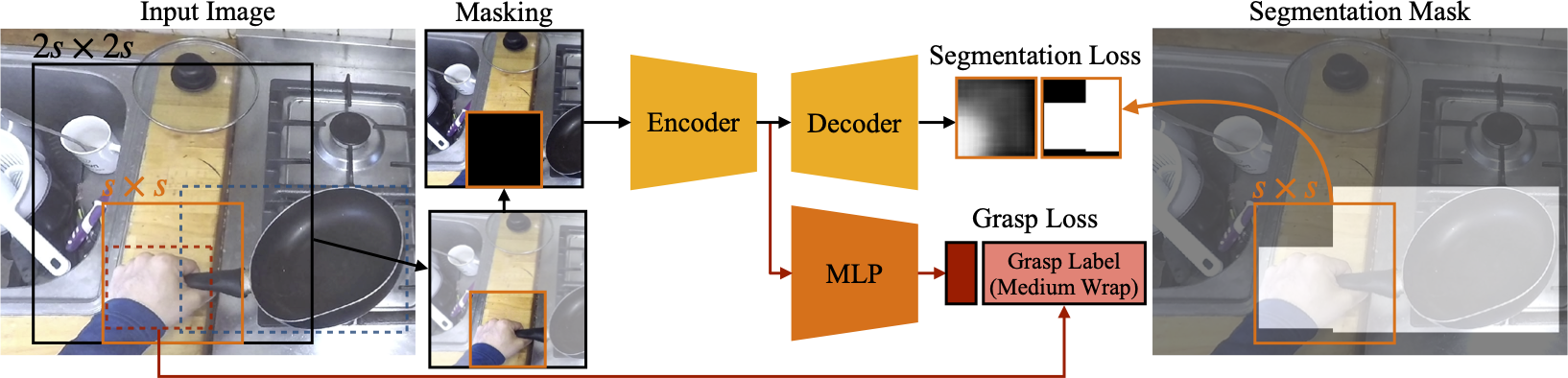
| Approach. To learn object affordances, we learn to predict the underlying location of hand-object pair and the corresponding hand grasp. To avoid a trivial solution, we setup a context prediction task where we mask the hand such that model can only use the surrounding context to make a prediction. |

|
||
| Results. For the input image (shown in (a)), we show the predicted regions of interaction in (b). Our method successfully detects multiple possible regions of interaction: bottles, jars, general objects in the fridge, and door knobs. We also visualize the per-pixel probability of affording the sphere 3 finger grasp in (c), and small diameter grasp in (d). The sphere 3 grasp is predicted for the door-knob, bottle caps and cans; while the small diameter grasp is predicted for bottles, jars and cans. |
EPIC-STATES Benchmark
 |
||
| Dataset Description. 14,346 object crops obtained from EPIC-KITCHEN dataset and annotated for object states. The dataset consists of 13 object categories and 10 object states. |
EPIC-RoI Benchmark
 |
||
| Dataset Description. 103 diverse in-the-wild images covering 9 kitchens from EPIC-KITCHENS dataset and densely annotated for regions of interaction (ROI). Each region is also factored into 4 possible classes, COCO Objects, Non-COCO objects, COCO parts and Non-COCO parts. |
 |
Mohit Goyal, Sahil Modi, Rishabh Goyal, Saurabh Gupta Human Hands as Probes for Interactive Object Understanding Computer Vision and Pattern Recognition (CVPR) 2022 paper / bibtex / code and data |
Acknowledgements
|
|